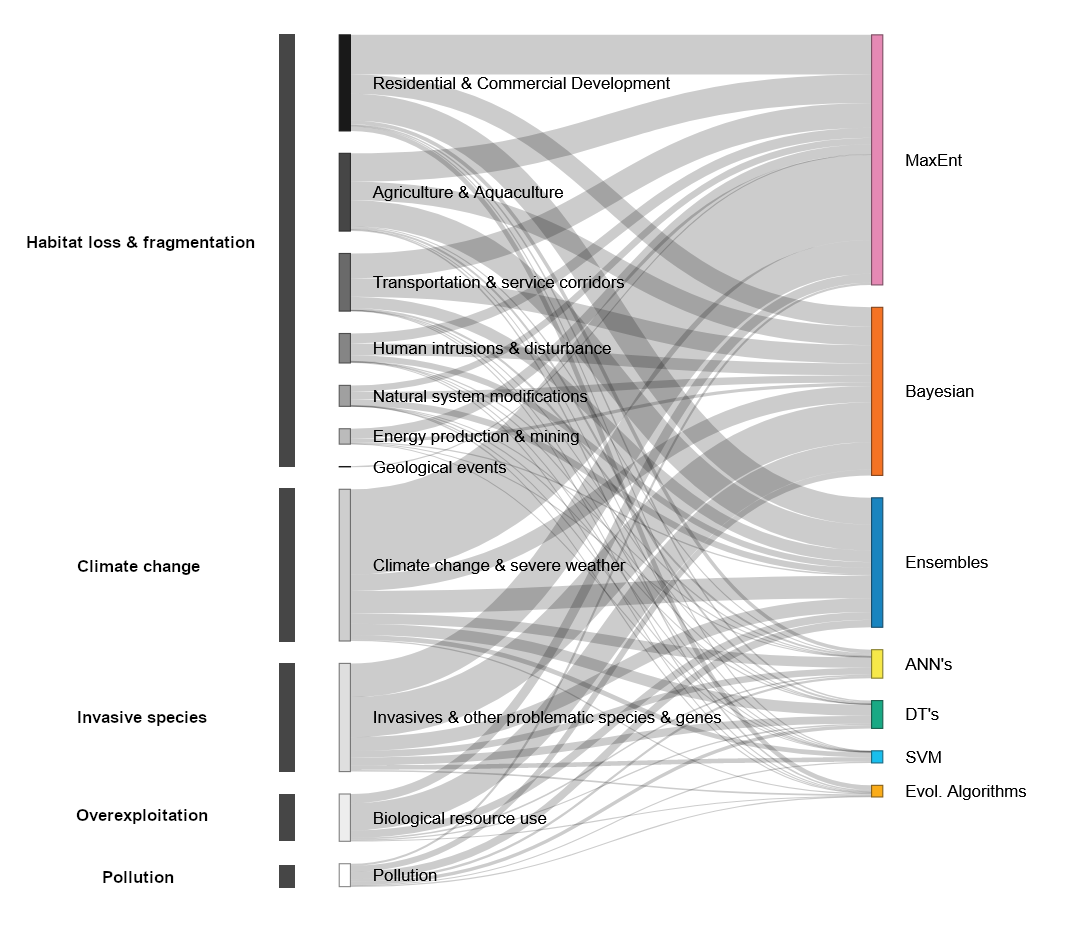
AbstractMachine learning is a growing computational field that borrows concepts and methodologies from statistics and data science to create semi-autonomous programmes capable of adapting to a multitude of problems and decision-making scenarios. With its potential in big data analysis, machine learning is particularly useful for tackling global conservation problems that often involve vast amounts of data and complex interactions between variables. In this systematic review, we summarise the use of machine learning methods in the study of species threats and conservation measures, and their emergent trends. Maximum entropy, Bayesian and ensemble methods have gained wide popularity in the past years and are now commonly used for multiple problems. Their relevance to modern conservation issues (and associated data types), their relatively simple implementation, and availability in a variety of software packages are the most likely factors to explain their popularity. Neural networks, decision trees, support-vector machines and evolutionary algorithms have been used in more specific situations, with some applications showing promise in dealing with increasingly complex data and scenarios.